(summary ver.) Analyzing 65,000 Japanese news articles with AWS
I study Japanese, so I decided to create a Japanese word frequency list using news articles as the source data. To do this, I made a serverless ETL pipeline that processed 65,000 articles.
This post briefly summarizes my project. You can find all the code in my Github repo. You can also read the longer version of this post here, where I explain my motivations, design decisions, and code in more detail.
Technologies used:
- AWS (Lambda, DynamoDB, S3, Athena, SQS)
- Python (boto3 SDK, SudachiPy, beautifulsoup)
- Docker
- SQL (Athena/PrestoDB)
Table of contents
Requirements
Here are my requirements and how I fulfilled them:
1. I needed a data source that could provide at least 10,000 Japanese news articles
Common Crawl is a non-profit organization that crawls billions of web pages every month. Their data is freely accessible to the public in an S3 bucket, so I can access a large amount of data with few restrictions.
2. I had to avoid copyright issues with article use
I found that using Japanese news articles for my purposes is perfectly legal - see Articles 30-4 (第三十条の四) and 47-7 (第四十七条の七) of Japan’s Copyright Act (resource in Japanese).
3. I had to create a batch data pipeline that could tokenize the Japanese text, store it, and aggregate it
I chose AWS as my cloud provider for the data pipeline, due to its variety of services and generous free tier pricing.
“Tokenizing” a sentence means breaking it into individual words. Unlike in English, Japanese text doesn’t separate words by spaces, and other features of the language complicate things further. To tokenize Japanese, I used an open source Python library called SudachiPy.
4. The project must be coded in Python, and cost $10 or less
The boto3 library allowed me to make API calls to AWS services with Python.
I estimated that the total cost of the batch job would be roughly $3.10 - see the Notes section of the main blog post for the calculations.
Ultimately, the total cost of the project was 86 cents. My DynamoDB usage only cost 4 cents, and data transfer was $0. The biggest cost was 60 cents for EC2 - I temporarily left my Docker images in Cloud9, and got charged for storage until I moved them to ECR.
Design
I needed a batch data pipeline that worked like this:
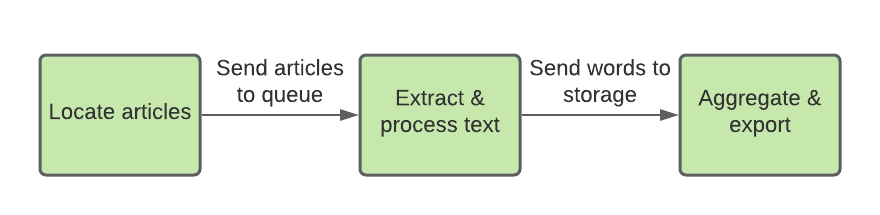
While considering my architecture, I tried to stay open-minded and consider the trade-offs of various options. I also made a post on a data engineering message board with an early design proposal, where I got lots of helpful feedback and ideas. I decided to adopt a serverless approach for my batch data pipeline, due to its scalability and low cost.
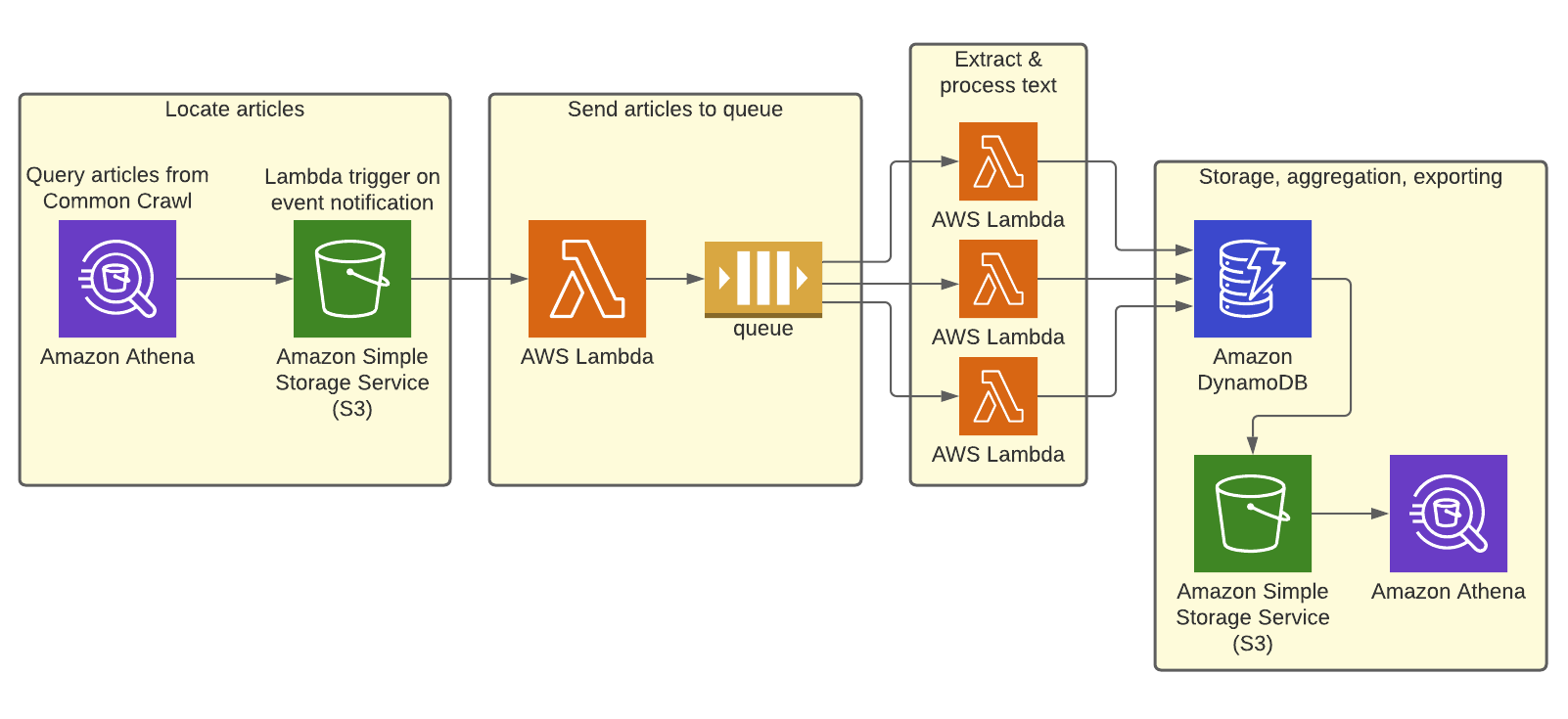
To start, I used Athena to query Common Crawl for news articles, and shuttled that data to a processing service via SQS. I needed to process a large number of fairly short articles, so I chose AWS Lambda for its concurrency, quick init time, and low cost. My tokenizer’s dependencies were large, so I had to bundle all Lambda code and dependencies in a Docker image.
With Lambda, I’d also need to use a database to handle a large number of concurrent writes to the data store. I considered two database services: RDS and DynamoDB. I chose DynamoDB because it can easily scale to high throughput.
However, DynamoDB doesn’t support aggregation natively. So, I stored un-aggregated words and counts in a DynamoDB table, then exported the data to S3. From there, I aggregated the data with Athena to get my final results.
Doing a data export makes this solution hard to scale - it would be costly and slow for a larger sample of articles. But, I chose to do this anyway because my project is a small, one-time batch job.
Here’s my finalized setup:
This setup fulfills all the requirements for my small project. For larger, more expensive workloads (i.e., several million articles), I’d definitely consider using AWS Batch to do extraction and tokenization, with storage in RDS.
How it works
Step 1: Find articles
- Use this Athena query I wrote to find 65,000 distinct Yahoo News Japan articles in the Common Crawl S3 bucket.
Step 2: Send articles to the queue
- Athena writes the query results (a CSV file of queried articles) to an S3 bucket I own. This triggers an S3 event notification.
- The event notification invokes the queueing Lambda to read the CSV file. The queueing Lambda sends the content of each row as a message to an SQS standard queue. View the queueing Lambda code here.
Step 3: Extract and process article text
- The processing Lambda has 19 concurrent instances. Each instance consumes a batch of up to 10 messages from the queue.
- For each article in its batch, the Lambda instance extracts the article web page, then parses and tokenizes the article text. The tokenized words are added to the pool of all unique words gathered during the batch.
- Once the full batch has been tokenized, the instance writes the unique words and counts to the DynamoDB table. You can view the processing Lambda code here.
Step 4: Store, aggregate, and export
- Once the batch job is finished, I have to manually export the table to S3.
- Finally, I have to register the table and run an aggregation query - this stores the top 5,000 most frequently appearing words and their counts in S3. Here’s the table registration query, and the aggregation query.
Conclusion

(View my code for generating the word clouds here!)
You can find the complete word list in my Github repo.
I learned so much by doing this project! I got hands-on experience working with many AWS services, used Docker for the first time, and got acquainted with NoSQL. I also learned the importance of following a good design process, thinking flexibly, and asking for help. I look forward to learning and building more.